개인 웹 사이트/홈페이지/웹 포트폴리오 등, 최근 인터넷에 올리는 모든 자료들은 AI 학습 / AI 크롤러의 위협을 늘 받고있습니다. SNS도 위험한데 개인 웹사이트까지 스스로 지켜야 하는 슬픈 현실에서 조금이나마 해결할 방법을 찾아보기로 합니다. 강제성이 없거나 완벽히 안전한 방식은 없다고도 하니, 일단 방지법들을 전부 때려붓기식으로 해봅시다.
1. robots.txt 설정 : 검색 엔진 및 AI 크롤러 차단
2. meta 태그로 웹 페이지 크롤링 차단 : 검색 엔진 및 일부 AI 차단
3. 이미지에 X-Robots-Tag HTTP 헤더 추가 : 이미지 크롤링 차단
4. Google Search Console에서 "검색 색인 제거" 요청 : 구글 검색 엔진 차단
5. 이미지 및 텍스트 보호 : 웹 스크래핑 차단
6. Cloudflare "Super Bot Fight Mode" 활용 : 웹 크롤러 차단
7. AI 크롤러 차단 요청 : OpenAI, Google 등
참고로, 다 하는 건 무리가 있으니 1~4번만 합니다.
1. robots.txt 설정
User-agent: Googlebot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: AnthropicAI
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
위 내용을 메모장에 복붙해서 robots.txt 이름으로 저장합니다.
그리고 웹사이트 루트 디렉터리에 위 robots.txt 파일을 추가하여 특정 크롤러가 접근하지 못하도록 할 수 있습니다.
- 웹사이트 루트 디렉터리: 일반적인 개인 홈페이지에서는 public_html 폴더 안에 넣으면 됩니다.
http://example.com/robots.txt 이렇게 넣었을 때 파일의 내용이 보이면 정상적으로 넣은 것
위 설정은 구글, OpenAI (ChatGPT), Anthropic (Claude), Common Crawl, Perplexity AI 크롤러를 차단합니다. 하지만 robots.txt는 강제력이 없으므로, 악의적인 크롤러는 무시할 수 있습니다.
2. meta 태그로 웹 페이지 크롤링 차단
<meta name="robots" content="noai, noimageai, noindex, nofollow">
각 웹 페이지의 <head> 태그에 다음 메타 태그를 추가하면 대부분의 검색 엔진이 크롤링하지 못합니다. 이를 적용하면 구글을 비롯한 일반 검색 엔진이 해당 페이지를 색인하지 않으며, 일부 AI 크롤러도 따라야 합니다.
정확히 어디에 넣어야할지 모르겠다면, 대충 head.php / index.php 이런 파일을 뒤적거리며 head 태그가 있는지 확인해보면 됩니다. 홈페이지에 게시판이 여러개일 때 모든 페이지를 보호해야 하므로, 모든 페이지에서 호출되는 head 파일이 가장 적합합니다. (tail, footer 는 권장X)
3. 이미지에 X-Robots-Tag HTTP 헤더 추가
<FilesMatch "\.(jpg|png|gif|webp|svg)$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>
<!-- Apache (htaccess 설정 예시) -->
서버 설정을 통해 AI 및 검색 엔진이 이미지 크롤링을 하지 못하도록 설정할 수 있습니다. 여기서부터 머리가 아픕니다.
일반적인 호스팅사는 Apache 를 사용하고 있으니, Apache 만 예시를 들겠습니다.
- FTP 또는 파일 관리자에서 public_html/.htaccess 파일을 찾기
- htaccess 파일이 없으면 직접 만들어야 합니다.
- htaccess 파일 생성
- 위 코드를 그대로 메모장에 복붙해서 .htaccess (앞에 온점 포함) 파일을 생성합니다.
- public_html/.htaccess 경로가 되도록 파일을 업로드 합니다.
- 이 설정은 .jpg, .jpeg, .png, .gif, .webp, .svg 파일에 대해 X-Robots-Tag 헤더를 추가하여 AI 크롤러가 크롤링하지 못하게 합니다. 텍스트 콘텐츠도 AI 크롤러 차단을 하려면 [html|php|txt|md|json] 확장자를 추가합시다.
- 파일 저장 후 적용 확인
- 설정이 제대로 적용되었는지 확인하려면, 웹 브라우저의 개발자 도구(F12) → 네트워크 탭에서 이미지 요청을 확인하면 됩니다.
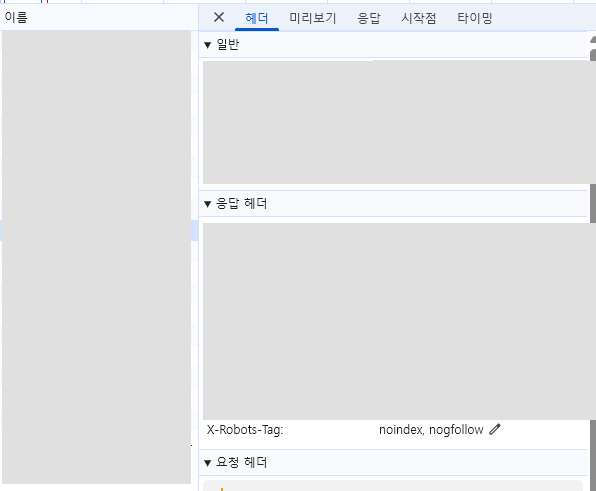
- 이미지 응답 헤더에 X-Robots-Tag: noindex, nofollow 가 포함되어 있으면 정상적으로 적용된 것입니다.
제대로 적용됐는지 확인하려면 아래 더보기에서 참고하세요.
<크롬 개발자 도구에서 X-Robots-Tag 확인하는 방법>
1. 개발자 도구 열기 (F12)
- 웹사이트에 접속한 후 F12 키 또는 Ctrl + Shift + I (Mac: ⌘ + Option + I)를 눌러 개발자 도구(DevTools)
2. "네트워크(Network)" 탭 클릭
- 상단 메뉴에서 "Network" (네트워크) 탭을 선택.
- 네트워크 탭이 보이지 않으면 오른쪽 >> 버튼을 눌러 찾아볼 것.
3. 페이지 새로고침 (F5 또는 Ctrl + R)
- 개발자 도구를 연 상태에서 페이지를 새로고침해야 모든 네트워크 요청이 로드됨.
4. 확인할 이미지 클릭
- 네트워크 탭에서 이미지 파일(.jpg, .png, .gif, .webp 등) 을 찾음.
- 찾는 방법: 필터(Filters) 박스에 "img" 입력하면 이미지 파일만 표시됨.
- 원하는 이미지를 클릭하여 상세 정보 창을 염.
5. "Headers" (헤더) 탭 클릭
- 이미지 상세 정보 창에서 "Headers" (헤더) 탭 선택.
6. X-Robots-Tag 헤더 확인
- 아래쪽으로 스크롤하여 "Response Headers" (응답 헤더) 섹션 찾기.
- "X-Robots-Tag: noindex, nofollow"가 포함되어 있는지 확인.
4. Google Search Console에서 "검색 색인 제거" 요청
Google Search Console 접속:
- Google Search Console 로그인 > 시작하기
- 자신의 사이트를 추가하고 도메인 소유권 인증

도메인 소유권 인증을 하려면 위 두 방법 중 하나를 선택해야 합니다.
웹서버를 만들었다면 DNS인증이 가능하지만, 일반 호스팅사(카페24/닷홈/아이비호스팅 등)을 이용했다면 오른쪽의 URL 접두어를 선택하고 도메인을 입력하세요.

확인방법은 여러가지 방법 중에서 선택할 수 있고, 솔직히 html 파일이 가장 무난합니다.
다운로드 후 robots.txt 처럼 루트 디렉토리에 업로드하면 끝입니다.
- "색인 삭제 요청" 진행:
- 소유권 확인이 끝나면 접속하는 구글 서치 콘솔 페이지 왼쪽 메뉴에서 "삭제" 선택
- "새 요청" 클릭 → URL 입력 후 삭제 요청
- robots.txt 업데이트 후 색인 삭제 요청 반복
- robots.txt에 Google-Extended 차단 추가 후 다시 삭제 요청 진행
이렇게까지 하고 나면, 그래도 무방비로 방치하는 것보다는 AI 학습을 막을 수 있습니다.